
the rapidly evolving landscape of AI, DeepSeek has introduced a groundbreaking solution to one of the most significant bottlenecks in large-scale AI model training and inference. DeepEP, the first open-source Expert Parallelism (EP) communication library, promises to revolutionize how Mixture-of-Experts (MoE) models are deployed and scaled.
If you’re leveraging AI for image, video, or text-based generation, Anakin AI’s cutting-edge tools, including Flux 1.1 Pro Ultra, Stable Diffusion XL, and Minimax Video 01, will take your creativity to the next level.
🔥 Seamlessly integrate AI models like GPT-4o, Claude 3, and Gemini for next-gen inference.
⚡ Optimize compute resources with automated AI pipelines and intelligent agent deployment.
💡 Leverage advanced image, video, and text generation models to accelerate your AI innovations.
🚀 Supercharge your AI workflows today! Try Anakin AI now:
🔗 Explore Anakin AI


Why MoE Models Matter
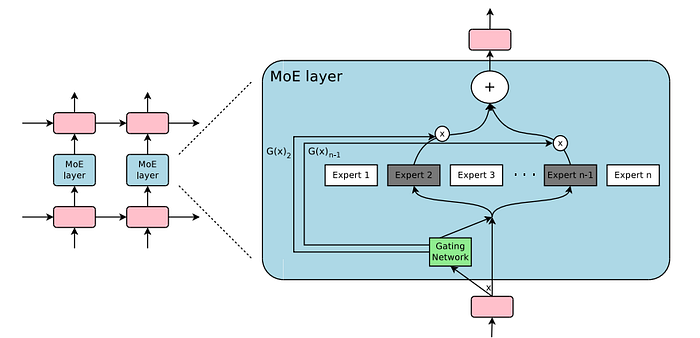
MoE models are quickly becoming the darling of AI research. Instead of overloading a single network, these architectures activate only the “expert” neural networks needed for a specific task, making them incredibly efficient. Imagine having a team of specialists, each handling their part of the workload, rather than one jack-of-all-trades. That’s the magic behind MoE — allowing massive models to scale to trillions of parameters without blowing up computational costs.
The Communication Challenge
However, every rose has its thorn. As MoE models grow, so does the need to efficiently route tokens to the right experts, whether they’re on the same GPU or spread across different nodes. Traditional communication libraries just weren’t built for this kind of all-to-all data exchange. The result? Training slowdowns, increased inference latency, and underutilized hardware. When you’re racing against time and costs, every microsecond counts.
DeepSeek DeepEP Unwrapped: What It Is, What It Does, and How It Works

You might be asking, “What exactly is DeepSeek DeepEP?” Well, let’s break it down in plain English. DeepEP is an open-source communication library crafted by DeepSeek. It’s specifically designed to ease the heavy lifting in MoE models — those models that split tasks among many specialized experts. In essence, DeepEP makes sure that every bit of data finds its way to the right expert quickly and smoothly.
What Does DeepEP Do?
Simply put, DeepEP streamlines the data shuffling between experts. It takes care of dispatching input tokens to the appropriate experts and then efficiently collecting the results. By doing so, it cuts down on the lag and bottlenecks that usually slow down training and inference in large-scale AI systems.
How Does It Work?
DeepEP harnesses high-speed communication technologies:
- Inside a Machine: It uses NVIDIA’s NVLink to move data at a blazing 153 GB/s. Think of it like a high-speed conveyor belt inside a busy kitchen, where every ingredient reaches its destination without delay.
- Across Machines: For communication between different machines, DeepEP relies on RDMA over InfiniBand, reaching speeds up to 47 GB/s. Imagine a well-coordinated delivery service that ensures orders are sent and received in record time.
- Precision Management: With native FP8 support, DeepEP cuts memory usage significantly while keeping the model’s accuracy intact — kind of like packing a suitcase more efficiently without leaving out the essentials.
Example in Action:
Imagine you’re running a restaurant during the dinner rush. Orders (input tokens) come in and need to be sent to the right chef (expert) for their specialty dish. Traditional systems might mix up orders or delay deliveries, leading to slow service and frustrated customers. With DeepEP, each order is quickly dispatched to the correct chef, and the finished dish is promptly sent back to the waiter (combined result), ensuring that every guest gets their meal on time. This streamlined process is exactly what DeepEP does for MoE models — making sure every piece of data is handled swiftly and accurately.
Real-World Impact
The benefits of DeepEP aren’t just theoretical — they’re already making waves in real-world applications. Early users have reported:
- 55% faster token processing during training, which means more data is handled in less time.
- 30% reduction in iteration time, shaving off precious seconds (or even minutes) during model runs.
- Improved power efficiency — it’s greener, too, helping cut energy costs while cranking up performance.
These improvements aren’t just numbers on a page; they translate into tangible savings in cloud costs, faster experiment cycles, and a significant boost in scalability. Whether you’re training massive language models or powering real-time video analytics, DeepEP is proving its worth across the board.
Looking Ahead
DeepEP isn’t resting on its laurels. The roadmap looks pretty exciting:
- Optical interconnects promise even higher throughput — think 800 Gb/s.
- Automated precision adaptation is on the horizon, dynamically switching between FP8, FP16, and FP32 to get the best of speed and stability.
- Some even hint at quantum-inspired routing, which sounds like science fiction but could very well be the next big leap in token dispatch efficiency.
The Verdict
So, what’s the final word on DeepEP? It’s a breath of fresh air for anyone working with MoE models. By tackling one of the toughest bottlenecks in AI training and inference, DeepEP not only boosts speed and efficiency but also democratizes access to high-performance communication tools through its open-source nature. Experts across the board are raving about its ability to balance technical rigor with practical, real-world benefits.
In a nutshell, DeepEP is turning the tables on traditional communication challenges in AI. It’s a tool that’s not only pushing the boundaries of what’s possible but also making the entire process smoother, faster, and more energy-efficient. For those in the AI community, this is one breakthrough you’ll want to keep your eyes on.
As the saying goes, when the going gets tough, the tough get going — and with DeepEP, the future of distributed AI looks brighter than ever.
from Anakin Blog http://anakin.ai/blog/deepep-transforming-communication-for-moe-models-day-2-of-deepseek-opensourceweek/
via IFTTT

No comments:
Post a Comment