Introduction: A Leap into the Open Source, Free AI Voice Clone Tool

Imagine the first time you heard a voice from a machine that sounded unmistakably human. The mix of wonder and disbelief, the curiosity about how far this technology could go. Fast forward to today, and we're standing on the brink of a new era with GPT-SoVITS, a tool that's not just pushing the boundaries but redefining them. This isn't just about machines talking; it's about them speaking with a voice that carries the nuance, emotion, and uniqueness of human speech. Welcome to the future of voice technology.
Article Summary
- GPT-SoVITS revolutionizes text-to-speech (TTS) with zero-shot and few-shot learning, enabling highly realistic voice cloning with minimal data.
- The platform offers cross-lingual support and a suite of WebUI tools, making it accessible for users to create custom TTS models.
- Installation and running GPT-SoVITS vary by platform, with guidance available for Windows, Mac, Kaggle, and Google Colab users.
Want to explore more AI Voice Generator Tools?
Looking for a cheaper Elevenlabs Alternative?
Try out Anakin AI's AI Voice Cloning Tool! Where you can easily clone AI Voice with your own dataset!
Key Features of GPT-SoVITS
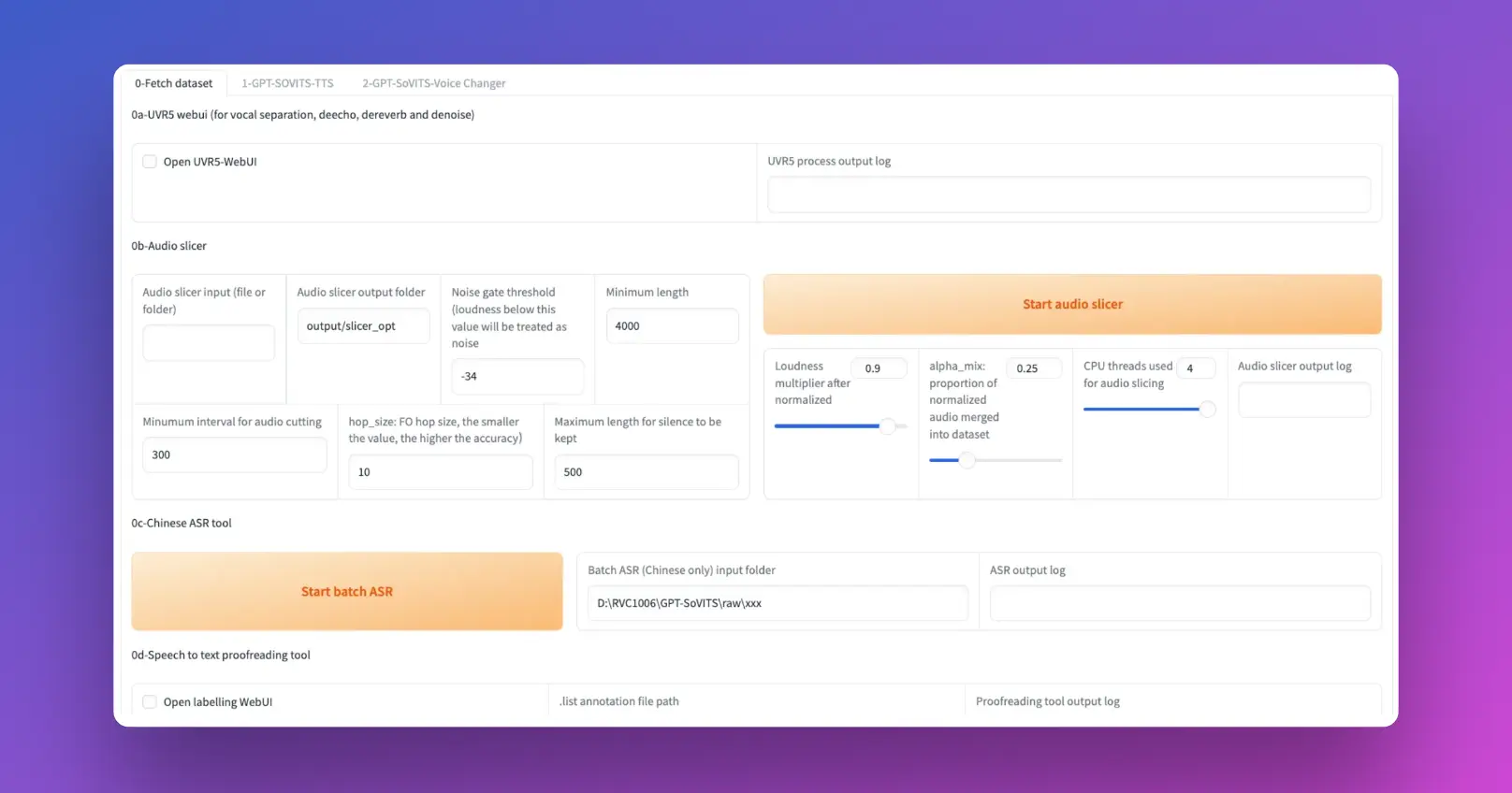
GPT-SoVITS is not just a tool; it's a breakthrough in voice technology that brings several innovative features to the table. Let's explore these features in detail:
Zero-shot TTS: A Glimpse into the Future
- Instant Voice Cloning: With zero-shot TTS, GPT-SoVITS can perform text-to-speech conversion using just a 5-second sample of any voice. This feature is akin to capturing the essence of a voice in a snapshot and then bringing written words to life with that very voice, all without the need for extensive training data.
Few-shot TTS: Crafting Realism with Minimal Data
- Enhanced Voice Similarity: The few-shot TTS capability of GPT-SoVITS is nothing short of magical. By training the model with just 1 minute of voice data, it can achieve a remarkable level of voice similarity and realism. This is especially beneficial for creating personalized voice assistants, audiobooks, or any application where voice uniqueness is key.
Cross-lingual Support: Breaking Language Barriers
- Multilingual Inference: One of the standout features of GPT-SoVITS is its ability to infer in languages different from the training dataset. Currently, it supports major languages like English, Japanese, and Chinese. This cross-lingual support opens up a world of possibilities for global communication and content creation, making it a versatile tool for users around the world.
Integrated WebUI Tools: Empowering Creators
- Comprehensive Toolkit: GPT-SoVITS comes with an integrated suite of WebUI tools designed to simplify the process of voice cloning and TTS model creation. These tools include:
- Voice Accompaniment Separation: Isolate vocals from background music, making it easier to create clean training datasets.
- Automatic Training Set Segmentation: Streamline the creation of training sets by automatically segmenting voice data.
- Chinese ASR and Text Labeling: These features assist users in transcribing and labeling voice data in Chinese, facilitating the training of TTS models with Chinese language support.
Together, these features make GPT-SoVITS a comprehensive solution for anyone looking to explore the frontiers of voice technology, from hobbyists and content creators to researchers and professionals in the field.

How to Install GPT-SoVITS: Preparing the Environment for the Free AI Voice Clone Tool
Setting up GPT-SoVITS requires specific preparations based on your operating system. Here's a step-by-step guide to ensure you're ready to dive into the world of advanced voice synthesis with GPT-SoVITS.
For Windows Users:
- Essential Downloads: Windows users need to download
ffmpeg.exeandffprobe.exe. These are crucial for handling multimedia files and should be placed directly in the GPT-SoVITS root directory. This allows GPT-SoVITS to process audio files seamlessly. - Environment Setup: Begin by setting up a suitable Python environment. Using Conda is recommended for managing dependencies effectively.
For Mac Users:
- System Requirements: Mac users should check their system's compatibility, especially for GPU support. GPT-SoVITS is optimized for Macs with Apple silicon or AMD GPUs. Also, ensure your macOS version is 12.3 or later to leverage full GPU capabilities.
- Conda Environment: Similar to Windows, start by creating a Conda environment. This isolates your GPT-SoVITS setup from other Python projects, ensuring dependency management is hassle-free.
Installation Steps:
Conda Environment Creation:
- Execute
conda create -n GPTSoVits python=3.9to create a new environment named 'GPTSoVits' with Python 3.9. This version is chosen for its compatibility with GPT-SoVITS requirements. - Activate the new environment with
conda activate GPTSoVits.
Dependency Installation:
- Install the necessary Python packages using
pip install -r requirements.txt. This command reads all the dependencies listed in therequirements.txtfile and installs them in your Conda environment.
FFmpeg Installation:
- Windows: After downloading
ffmpeg.exeandffprobe.exe, ensure they are in the GPT-SoVITS root directory. - Mac: Use Homebrew to install FFmpeg by running
brew install ffmpeg. This simplifies the installation process and ensures that FFmpeg integrates well with your system.
Final Checks:
- Verify that all installations are successful and that the environment is correctly set up. Running a simple test, such as a Python script or command that uses GPT-SoVITS functionalities, can help confirm everything is in order.
By following these steps, you'll have a robust environment ready for exploring the capabilities of GPT-SoVITS, whether you're on Windows or Mac. This preparation ensures that you can focus on creating and experimenting with voice synthesis without worrying about technical hiccups.
How to Install GPT-SoVITS on Windows
Step-by-Step Guide:
Download Prezip File:
- Navigate to the GPT-SoVITS repository and download the prezip file tailored for Windows users.
Unzip the File:
- Locate the downloaded file on your computer and unzip it using your preferred archive manager.
Launch GPT-SoVITS:
- In the unzipped folder, find and double-click
go-webui.bat. This action will start the GPT-SoVITS WebUI, making the application ready for use.
Install FFmpeg (if needed):
- Download
ffmpeg.exeandffprobe.exefrom a trusted source. Place these files in the root directory of GPT-SoVITS to enable audio processing functionalities.
Pretrained Models:
- For enhanced functionality like voice separation or reverberation removal, download the additional pretrained models and place them in the specified directories within the GPT-SoVITS folder.
By following these steps, Windows users can easily set up GPT-SoVITS and explore its voice cloning capabilities.
How to Install GPT-SoVITS on Mac with Docker
Preparing Your Mac:
- Ensure your Mac is equipped with Apple silicon or AMD GPUs and is running macOS 12.3 or later.
- Install Xcode command-line tools by executing
xcode-select --installin the terminal.
Docker Installation:
Docker Setup:
- If not already installed, download and install Docker for Mac from the official Docker website.
Clone GPT-SoVITS Repository:
- Clone the GPT-SoVITS repository to your local machine using Git or download it directly from GitHub.
Navigate to GPT-SoVITS Directory:
- Open a terminal window and navigate to the cloned or downloaded GPT-SoVITS directory.
Docker Compose:
- Locate the
docker-compose.yamlfile within the GPT-SoVITS directory. Ensure it's configured according to your needs, adjusting environment variables and volume configurations as necessary.
Launch with Docker Compose:
- Run
docker compose -f "docker-compose.yaml" up -din your terminal. This command will start the GPT-SoVITS application within a Docker container.
Accessing GPT-SoVITS:
- Once the container is up and running, you can access the GPT-SoVITS WebUI through your web browser by navigating to the local address provided in the terminal output.
By utilizing Docker, Mac users can overcome compatibility issues and leverage GPT-SoVITS's advanced voice synthesis capabilities without direct installation on macOS.
Run GPT-Sovits AI Voice Cloning with Google Colab/Kaggle Notebook
Here's a detailed step-by-step guide to using GPT-SoVITS with Google Colab:
Step 1: Install GPT-SoVITS on Google Colab
Access Colab Notebook: Go to the provided Colab notebook link. Make sure you're logged into your Google account since Colab requires it. Alternatively, you can also use this Kaggle Notebook link.
Run the Notebook: Once the notebook is open, click on Runtime > Run all to start the installation process of GPT-SoVITS. This will automatically download and install the necessary software components.
Grant Permissions: During the setup, you might encounter pop-ups asking for permissions, especially for accessing Google Drive. You need to allow these to enable the notebook to interact with your Drive for storing and accessing files.
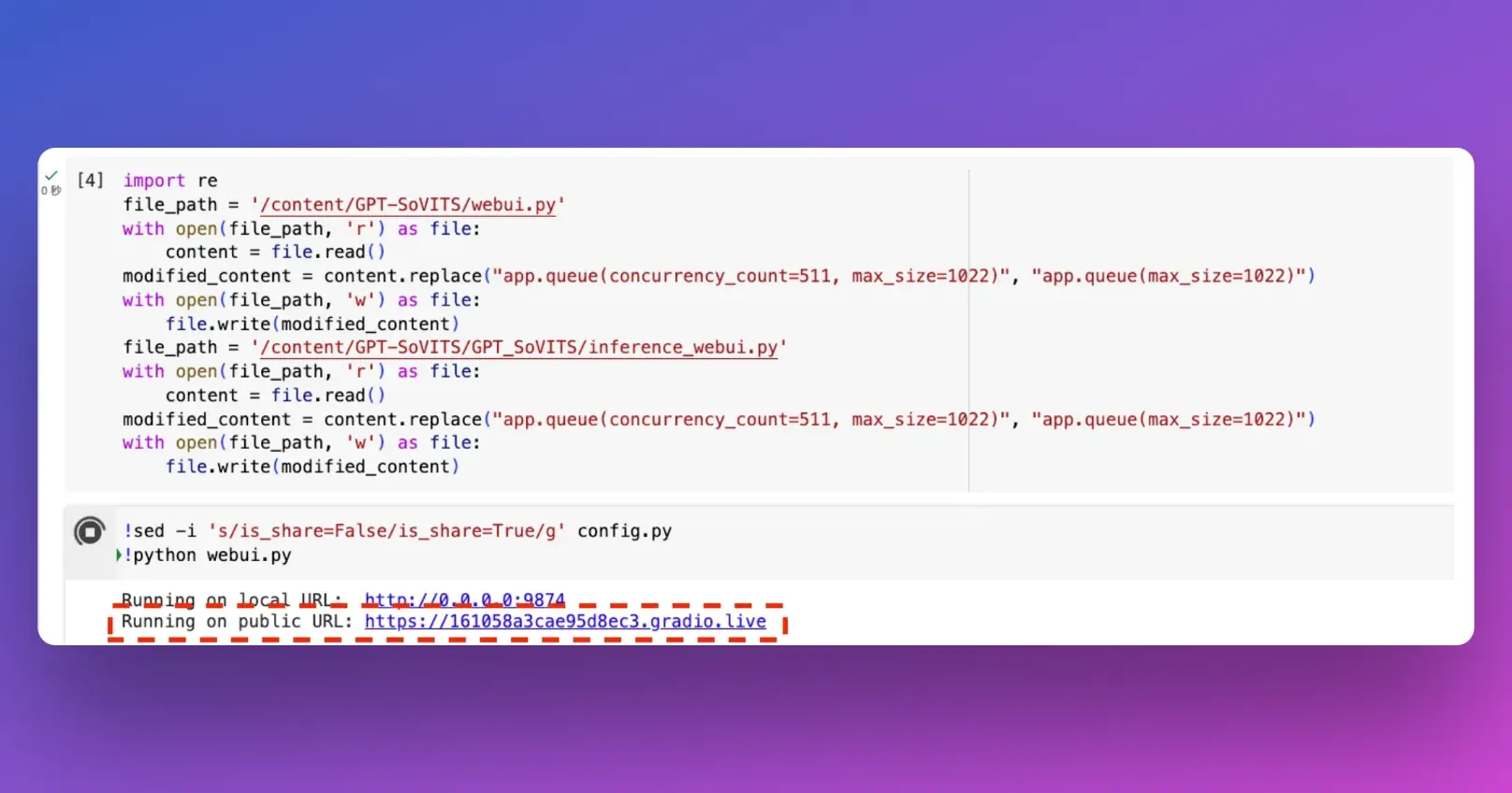
Step 2: Provide Training Voice Material
Prepare Voice Material: You need a 1-2 minute long voice recording, preferably with no background noise, in .wav format. Currently, only Chinese language training is supported.
Upload to Google Drive: In your Google Drive, create a new folder named voice_files. Inside this folder, create two subfolders: raw for the original voice files and slicer for the processed files. Upload your .wav files to the raw folder.
Step 3: Check Voice Recognition Accuracy
Run Audio Slicer: Back in the Colab notebook, locate the section for running the audio slicer, input the path to your raw folder (/content/drive/MyDrive/voice_files/raw), and execute the slicer. This will segment your audio file into smaller pieces suitable for training.
Automatic Speech Recognition (ASR): After slicing, provide the path to the slicer folder (/content/drive/MyDrive/voice_files/slicer) in the ASR section of the notebook and run the ASR process. This will transcribe the audio segments.
Verify Transcriptions: Once ASR is complete, it's essential to check the accuracy of the transcriptions. You can do this by accessing the generated .list file, which contains the transcriptions, and manually verifying them.
Step 4: Format Training Data
Organize Data: Ensure the transcribed audio files and their corresponding transcriptions are correctly formatted and organized. The expected format is usually a .list file with entries in the format: audio_file_path|speaker_name|language|transcription.
Upload Formatted Data: Upload this .list file along with the segmented audio files to the appropriate directories in your Google Drive, as specified by the Colab notebook instructions.
Step 5: Fine-tune Training
Initiate Training: In the Colab notebook, locate the section for fine-tuning the model. Input the necessary paths to your formatted data and start the training process.
Monitor Progress: Training might take a while, so monitor the progress through the logs provided in the Colab notebook. Ensure there are no errors, and the process completes successfully.
Step 6: Inference - Generate Voice from Text
Setup Inference: After training, set up the inference environment in the Colab notebook by providing the paths to the trained model weights.
Generate Voice: Input the text you want to synthesize in the voice model and run the inference. The model will generate voice output based on the text provided.
Download and Compare: Download the generated audio file and compare it with the original voice material to assess the quality and similarity.
By following these steps, you should be able to use GPT-SoVITS on Google Colab for voice cloning and text-to-speech synthesis. Remember to use the technology ethically and respect copyright and privacy laws. If you find this guide helpful, consider exploring more about GPT-SoVITS and voice synthesis technologies.
Pretrained Models and Dataset Format for GPT-SoVITS (Free AI Voice Clone Tool)
Pretrained Models:
To get started with GPT-SoVITS, you'll need to download and use pretrained models. These models have been trained on a vast dataset and can save you considerable time and resources.
Main Models: Download the primary pretrained models from the official GPT-SoVITS repository or model distribution page. Place these models in the pretrained_models directory within your GPT-SoVITS installation folder.
Specialized Tasks: For tasks such as vocal/accompaniment separation and reverberation removal, additional models are available. Download these specialized models and place them in the designated directories, typically within the tools or extensions folder of your GPT-SoVITS installation.
Dataset Format:
For Text-to-Speech (TTS) annotation, the dataset should be organized in a specific format. Each entry should include:
- Path: The relative or absolute path to the audio file.
- Speaker Name: Identifier for the speaker, useful for distinguishing between different voices.
- Language: The language code (e.g., 'en' for English, 'ja' for Japanese, 'zh' for Chinese).
- Text: The transcript of the audio in the corresponding file.
An example entry might look like: /path/to/audio.wav|John Doe|en|Hello, world!
Want to explore more AI Voice Generator Tools?
Looking for a cheaper Elevenlabs Alternative?
Try out Anakin AI's AI Voice Cloning Tool! Where you can easily clone AI Voice with your own dataset!
Advanced Features of GPT-SoVITS, How Good Is This Free AI Voice Clone Tool?
GPT-SoVITS is not just about cloning voices; it's equipped with advanced features that make it a versatile tool in the realm of TTS and voice synthesis:
Cross-lingual Support: GPT-SoVITS can generate speech in languages different from the training data, broadening its applicability across various linguistic contexts.
Integrated WebUI Tools: The platform includes a range of tools within its WebUI for tasks like voice separation, training set segmentation, and more, making it accessible even to beginners.
Future Plans & Road Map for Better Free AI Voice Cloning
The roadmap for GPT-SoVITS includes exciting developments:
Localization: Plans for localization in Japanese and English are underway, aiming to make the tool more user-friendly across different regions.
User Guides: Comprehensive user documentation is in the pipeline to help new users navigate the platform with ease.
Dataset Fine-Tuning: Enhancements in dataset fine-tuning for Japanese and English are expected, improving the quality and naturalness of the synthesized speech.
Ask your question about GPT-SoVITS on its GitHub repo.
Conclusion: The Future of Free, Open Source AI Voice Cloning?
GPT-SoVITS is reshaping the landscape of voice cloning and TTS technology. Its ease of use, minimal data requirements for personalization, and support for multiple languages make it a powerful tool for various applications. From content creation to personalized voice assistants, GPT-SoVITS offers a gateway to innovative voice synthesis capabilities. As the platform continues to evolve, its impact on the field is poised to grow, making voice technology more accessible and versatile than ever before.
Want to explore more AI Voice Generator Tools?
Looking for a cheaper Elevenlabs Alternative?
Try out Anakin AI's AI Voice Cloning Tool! Where you can easily clone AI Voice with your own dataset!
from Anakin Blog http://anakin.ai/blog/gpt-sovits-open-source-ai-voice-clone/
via IFTTT




No comments:
Post a Comment