Die Nachfrage nach unzensiertem NSFW-KI ist 2026 explodiert, angetrieben durch Fortschritte in Open-Source-Modellen wie Flux Dev und Sora-Klonen. Diese Plattformen umgehen Unternehmensfilter und bieten fotorealistische Nudes, Hentai, BDSM-Szenen und maßgeschneidertes Porn ohne Paywalls oder Verbote. Sie sind perfekt für Creator, Roleplayer und Fantasie-Explorer, die null Einschränkungen bei Erwachseneninhalt wollen. In diesem Artikel ranken wir die Top 5 kostenlosen Optionen basierend auf Benutzerfreundlichkeit, Ausgabequalität, Geschwindigkeit und filterfreier Freiheit. Jede bietet großzügige Free-Tiers (tägliche Credits, keine Karte nötig), hochauflösende Ausgaben (bis 4K) und Tools wie Text-zu-Bild, Bild-zu-Bild, Undress und Videogenerierung. Wir tauchen ein in Features, Vor-/Nachteile, Prompts und Tipps.
Ob Sie „Orgie mit großen Titten-Elfen“ oder „realistischen Celebrity-Deepfake-Nude“ generieren – diese übertreffen Groks gelegentliche Zögern. Lassen Sie uns die Besten entblößen.
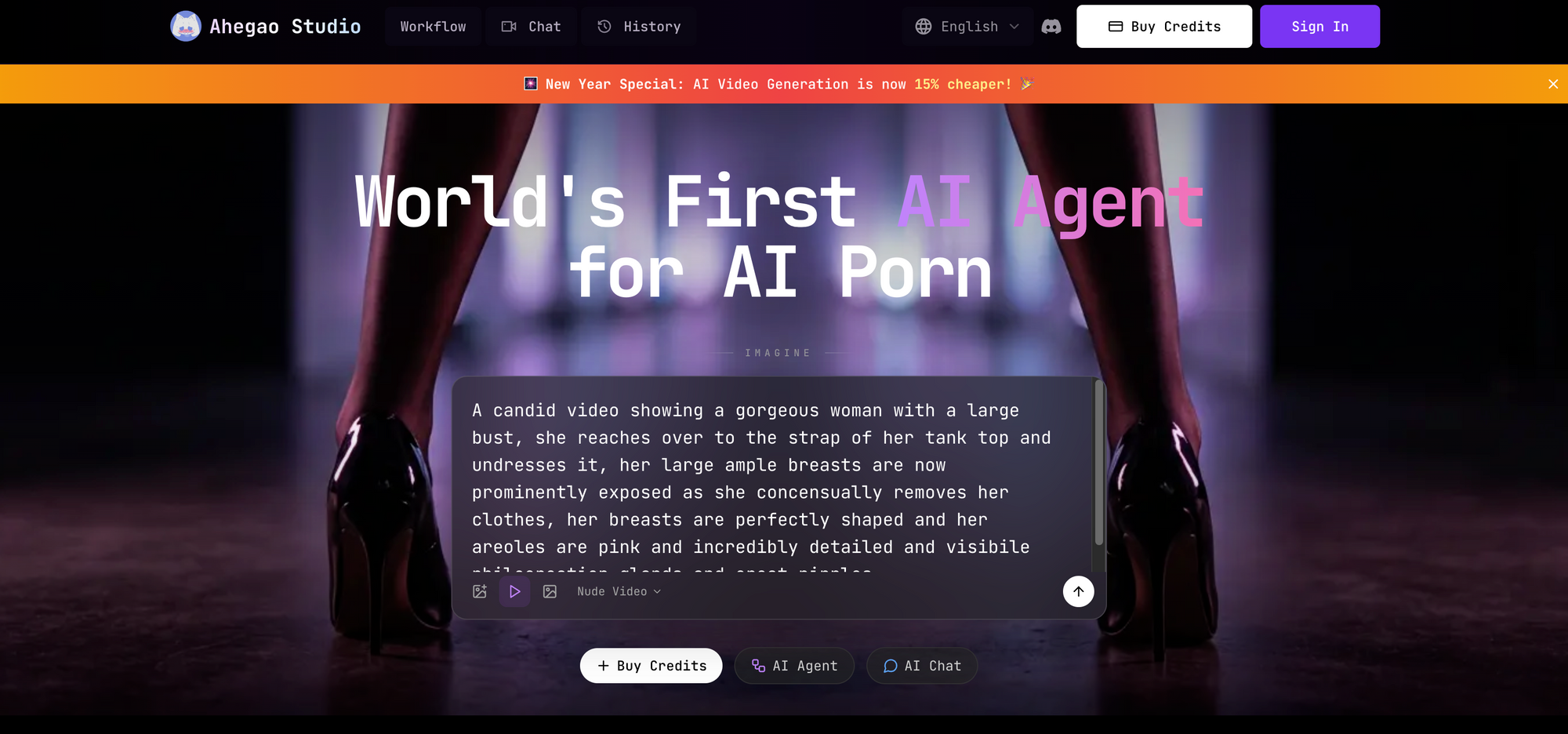
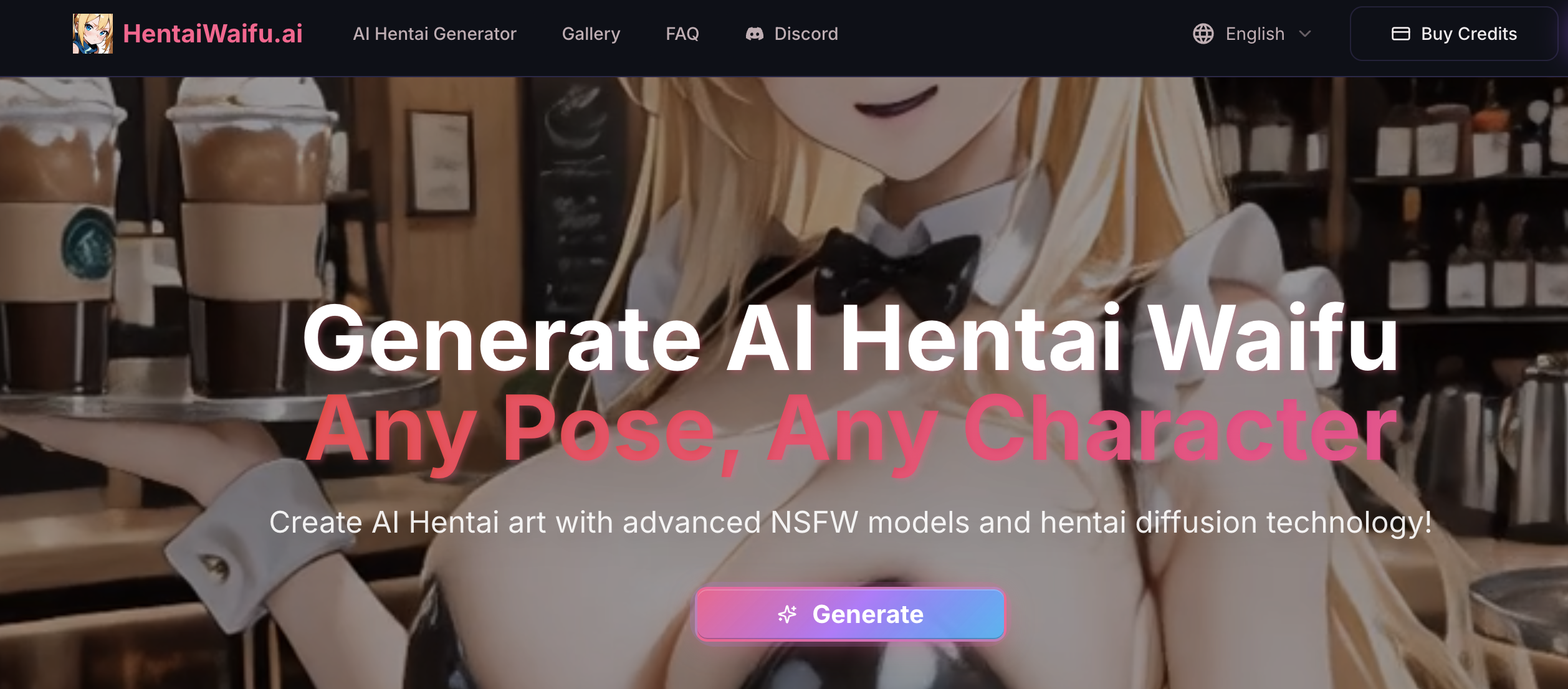
#1: FluxNSFW.ai – Das Ultimative Flux-gestützte NSFW-Monster
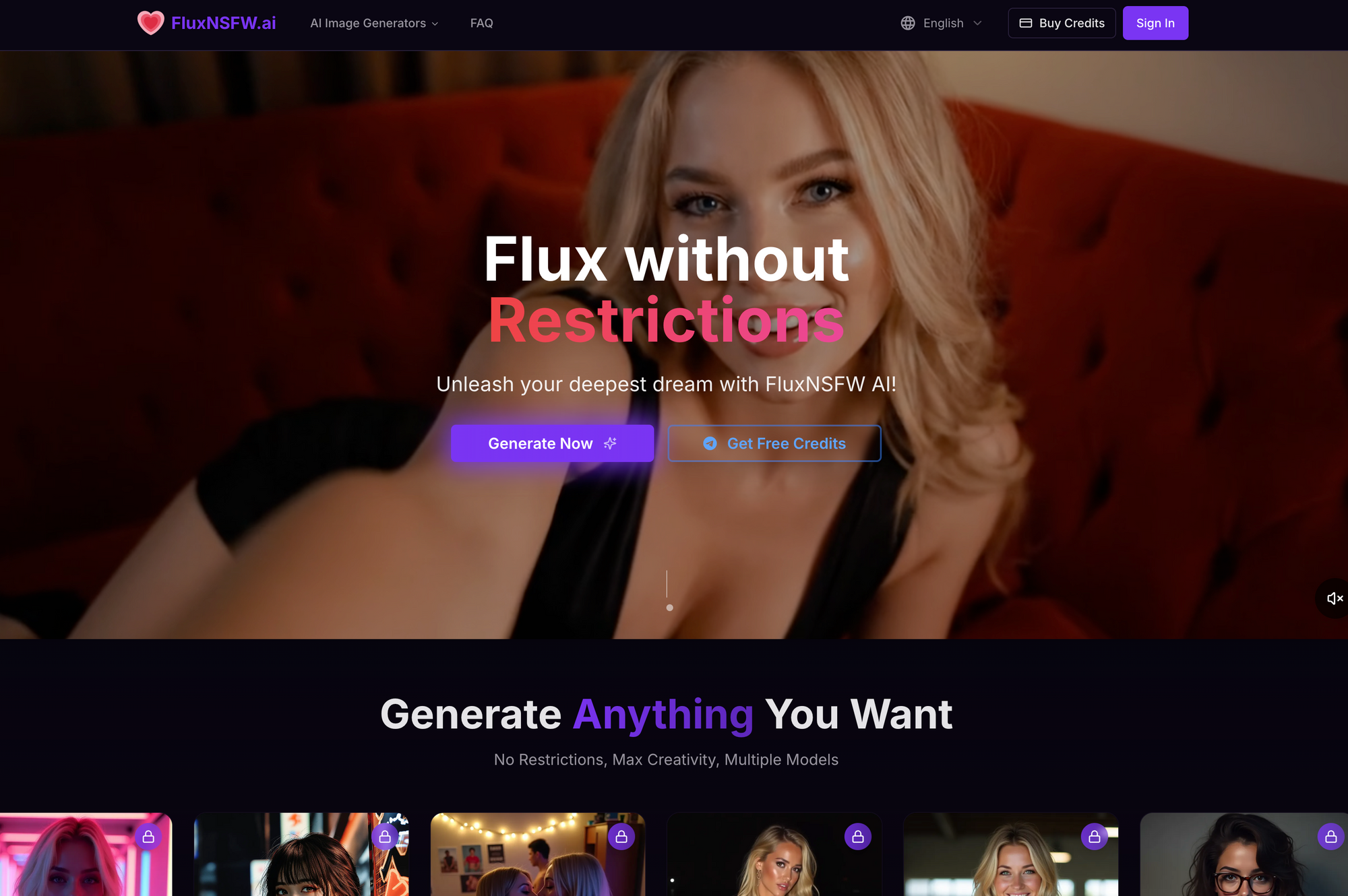
An der Spitze steht FluxNSFW.ai, eine Powerhouse, die das unzensierte Flux Dev-Modell für hyperrealistische KI-Pornogenerierung nutzt. Als rücksichtslose Alternative zu gefilterten Flux-Tools lanciert, spezialisiert sie sich auf Undress-AI, Deep-Nudes, Kleidungsentfernung und maßgeschneiderte Pornobilder/Videos. Free-Nutzer erhalten 50+ tägliche Generierungen, ohne anfängliche Anmeldung, skalierbar auf unbegrenzt mit optionalem Login.
Schlüsseleigenschaften:
- Instant Undress-AI: Laden Sie jedes Foto hoch (Celebrity, Selfie, Anime) – Kleidung weg in Sekunden, enthüllt anatomisch perfekte Nudes mit anpassbaren Posen, Beleuchtung und Ethnien.
- Text-zu-NSFW: Prompts wie „voluptuöse Rothaarige mit massiven Brüsten, spritzender Orgasmus, 8K realistisch“ erzeugen makellose Ergebnisse – keine Ablehnungen.
- Flux Dev Unzensiert: Umgeht alle NSFW-Blockaden, unterstützt Gore, Fetische, Loli (ethische Nutzung angenommen) und hyperdetaillierte Genitalien.
- Extras: Face-Swap, Inpainting (Bearbeitung spezifischer Körperteile), Batch-Generierung und Mobile-App.
So funktioniert's: Prompt eingeben > Stil wählen (realistisch, Hentai, 3D) > Generieren. Free-Tier: HD-Ausgaben, 10s-Videos. Vorteile: Blitzschnell (2-5s/Bild), überlegene Anatomie vs. Grok, Community-Prompt-Hub. Nachteile: Wasserzeichen bei Free-Videos (entfernbar per Upscale).
Im Vergleich zu Grok handhabt FluxNSFW.ai „illegale“ Prompts (z. B. Tabu-Fetische) ohne zu blinzeln, ideal für Profis. Pro-Tipp: „Negative Prompt: censored, blurry“ für Perfektion. Ethische Notiz: Nur konsensuell simulierter Inhalt.
FluxNSFW.ai sticht mit nahtloser Integration der Flux-Stärken heraus und liefert detailliertere, konsistentere Ergebnisse als Standard-Tools. Nutzer loben die Fähigkeit, komplexe Szenen mit mehreren Charakteren, dynamischer Beleuchtung und intricaten Texturen auf Haut und Stoffen zu generieren. Prompts wie „glänzender Schweiß auf Kurven“ oder „detaillierte Vene-Muster“ erzeugen professionelle Fotografie-ähnliche Ausgaben. Die Undress-Funktion wird für Präzision bei Körperformen und natürlicher Schattierung gefeiert, vermeidet Verzerrungen bei schwächeren Generatoren.
Erweiterte Anpassung erlaubt Feinjustierung mit Sliders für Brustgröße, Hüftverhältnis, Haarlänge und Erregungszustände wie „steife Nippel, geschwollene Schamlippen“. Dieser Kontrollgrad realisiert personalisierte Fantasien präzise. Video-Funktionen umfassen kurze Motion-Clips wie wippende Brüste oder stoßende Hüften mit smoother Frame-Interpolation. Free-Nutzer upscalen mühelos auf 4K – perfekt für Wallpapers, Drucke oder Teilen.
Bei Geschwindigkeit und Zugänglichkeit lädt die Site blitzschnell auf jedem Gerät, ohne Werbung, die den Kreativflow stört. Ideal für täglichen Einsatz, von Solo-Nudes bis Gruppenorgien. Für Grok-Migranten ist die Prompt-Syntax vertraut, aber verbessert – keine Workarounds nötig.
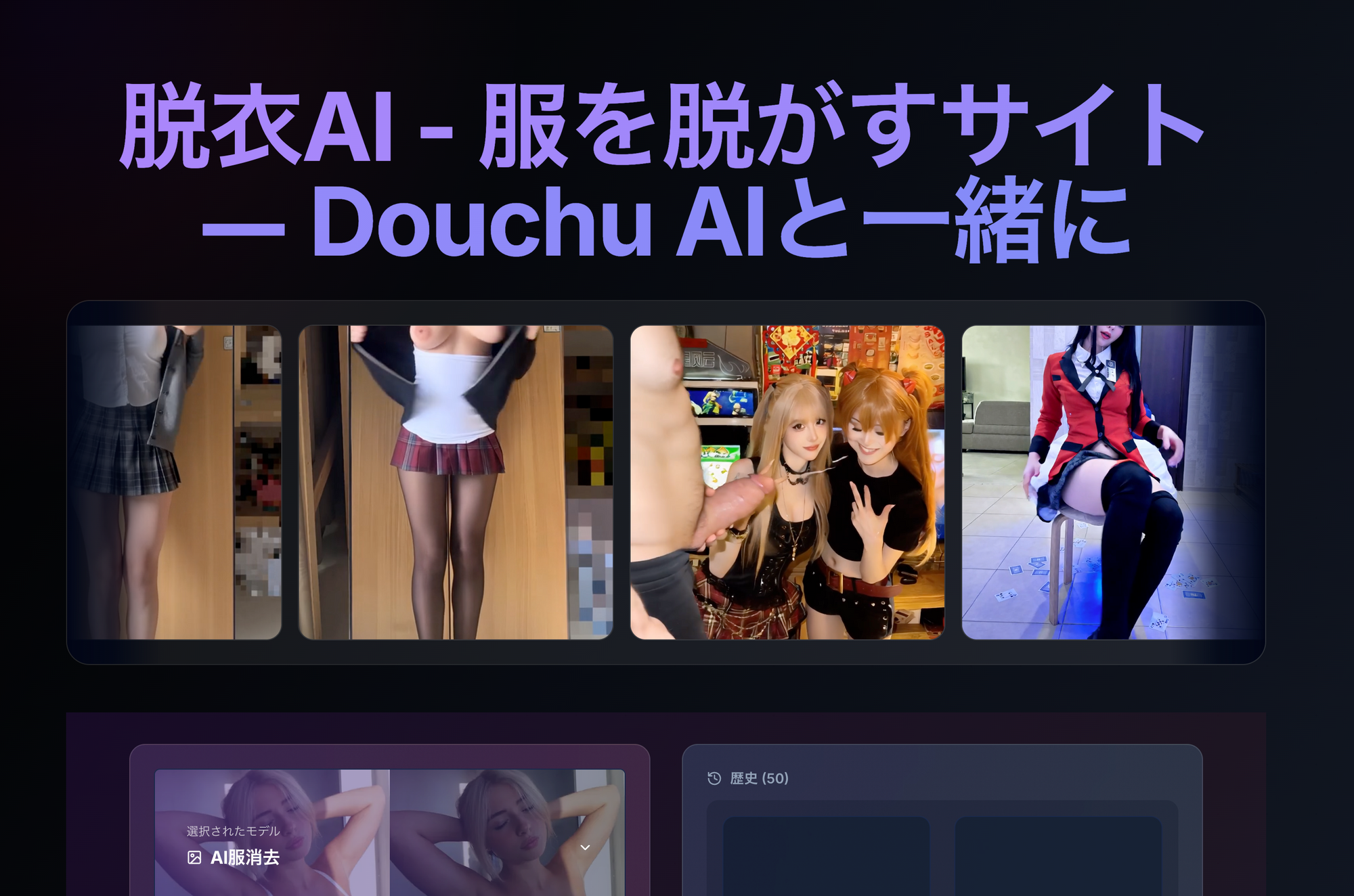
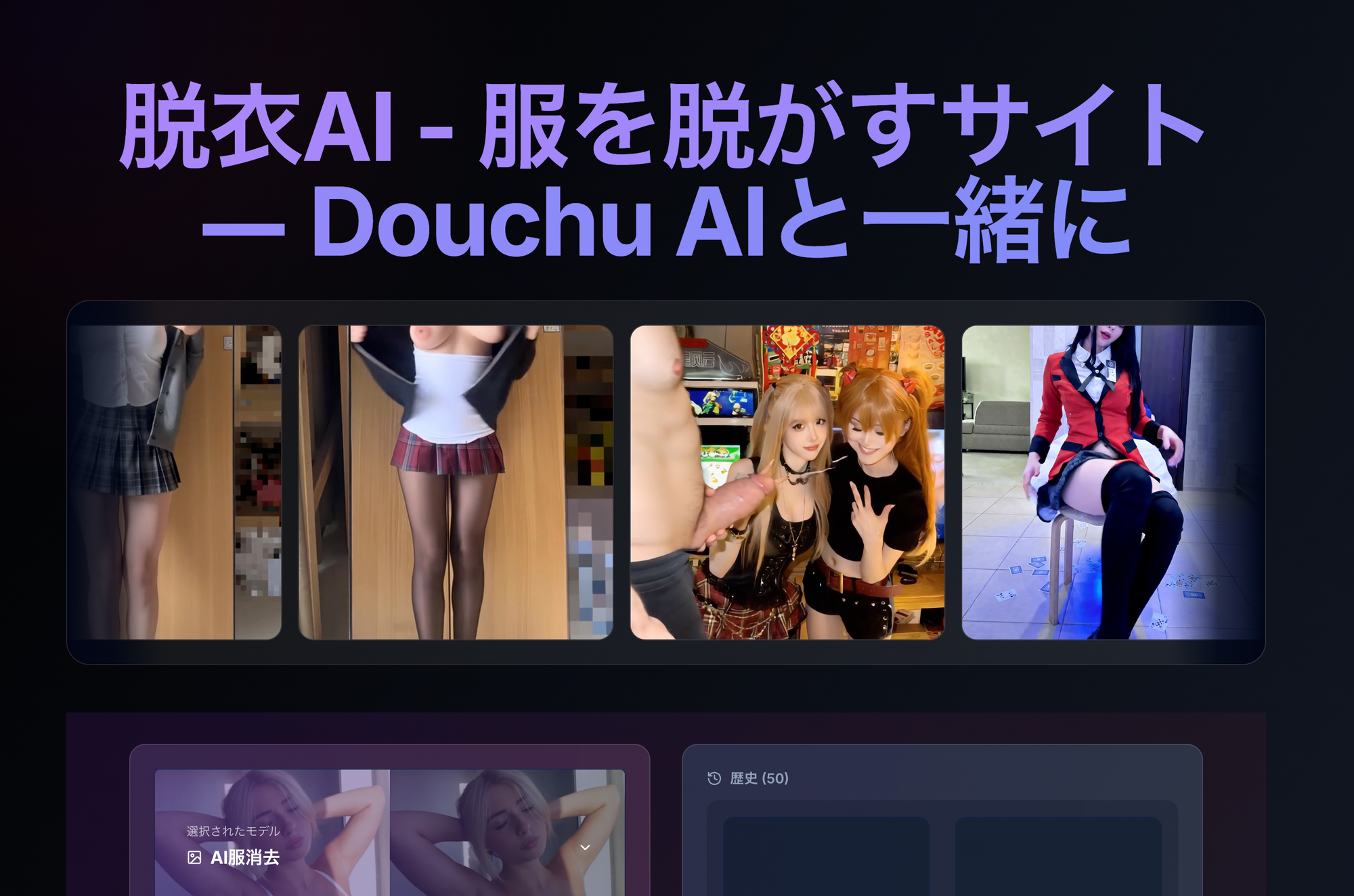
#2: Ahegao.studio – Ahegao- und Multi-Model-Pornofabrik
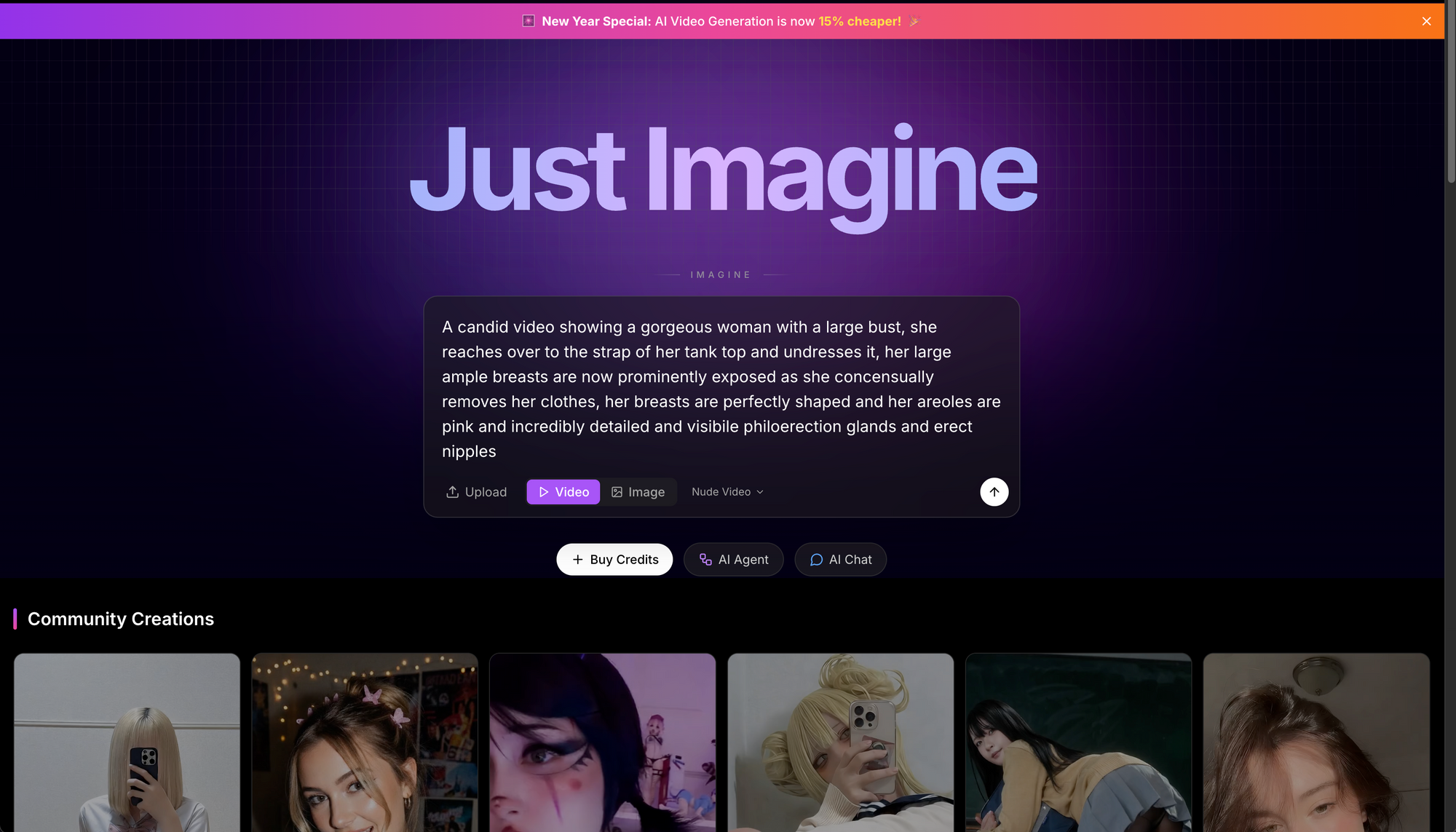
Ahegao.studio sichert Platz 2 durch Obsession mit übertriebenen Ekstase-Gesichtern (Ahegao) und bietet eine Voll-Spektrum-NSFW-KI-Suite: Nudes, Undress, Videos und 40+ Modelle. Free-Zugang umfasst 100 tägliche Credits, keine Limits bei Explizitheit – generieren Sie verrückte AI-Girls instant.
Schlüsseleigenschaften:
- AI-Girl-Generator 18+: Custom Waifus mit rollenden Augen, heraushängenden Zungen, Speichel und keuchenden Brüsten. Mischen mit Posen wie „Cowgirl auf Daddy“.
- Undress & Kleidungsentferner: Pro-Level-Deepfake-Nudes aus jedem Bild.
- Video-Modelle: Statik zu loopenden Orgasmen, Blowjobs oder Hentai-Loops animieren (bis 30s free).
- Manus AI-Core: Unzensiert; unterstützt VR-taugliche 360°-Views.
So funktioniert's: Prompt > Modell-Selektor (Flux, Stable Diffusion XL, Pony) > Mit Tags verfeinern. Ausgaben: 1024x1024+ free. Vorteile: Wahnsinnig vielseitig (Bilder/Videos/Chats), einsteigerfreundliche UI, Export als GIF/MP4. Nachteile: Warteschlange bei Peaks (Inkognito nutzen).
Übertrifft Grok bei NSFW-Videos und Mimik; perfekt für Anime-Fans. Sample-Prompt: „Ahegao-Schlampe mit rosa Nippeln, Creampie-Tropfen, ultra-detaillierte Muschi“.
Ahegao.studio glänzt bei Gesichtsdetails und fängt überwältigende Lust mit gekreuzten Augen, offenen Mündern und Speichelspuren lebendig ein. Multi-Modell-Ansatz erlaubt Wechsel von Fotoreal zu Cartoon mitten in der Session – ideal für Hybrid-Fantasien. Undress-Tools handhaben Schichten realistisch, simulieren Stoffablösen und Unterwäsche-Enthüllungen. Video-Generierung fügt Audio-Hinweise wie Stöhnen hinzu (TTS optional), steigert Immersion.
Das Tag-System ist robust: Über 500 Deskriptoren für Körpertypen, Outfits, Settings (Strand, Dungeon, Schlafzimmer) und Aktionen (Fingern, Anal, BDSM). Free-Credits erneuern stündlich für Marathons. Community-Presets beschleunigen Workflows, z. B. „Instant Office-Schlampe-Transformation“. Für VR-Fans umhüllen 360°-Ausgaben Szenen um den Betrachter, simulieren Präsenz.
Im Vergleich zu statischen Bildgeneratoren loopen Ahegao.studio-Animationen perfekt – ideal für hypnotischen Content oder GIFs. Ein kreativer Hub für schnelle Iterationen von groben Skizzen zu poliertem Porn.
#3: NSFWSora.ai – Soras Frecher Video-Zwilling
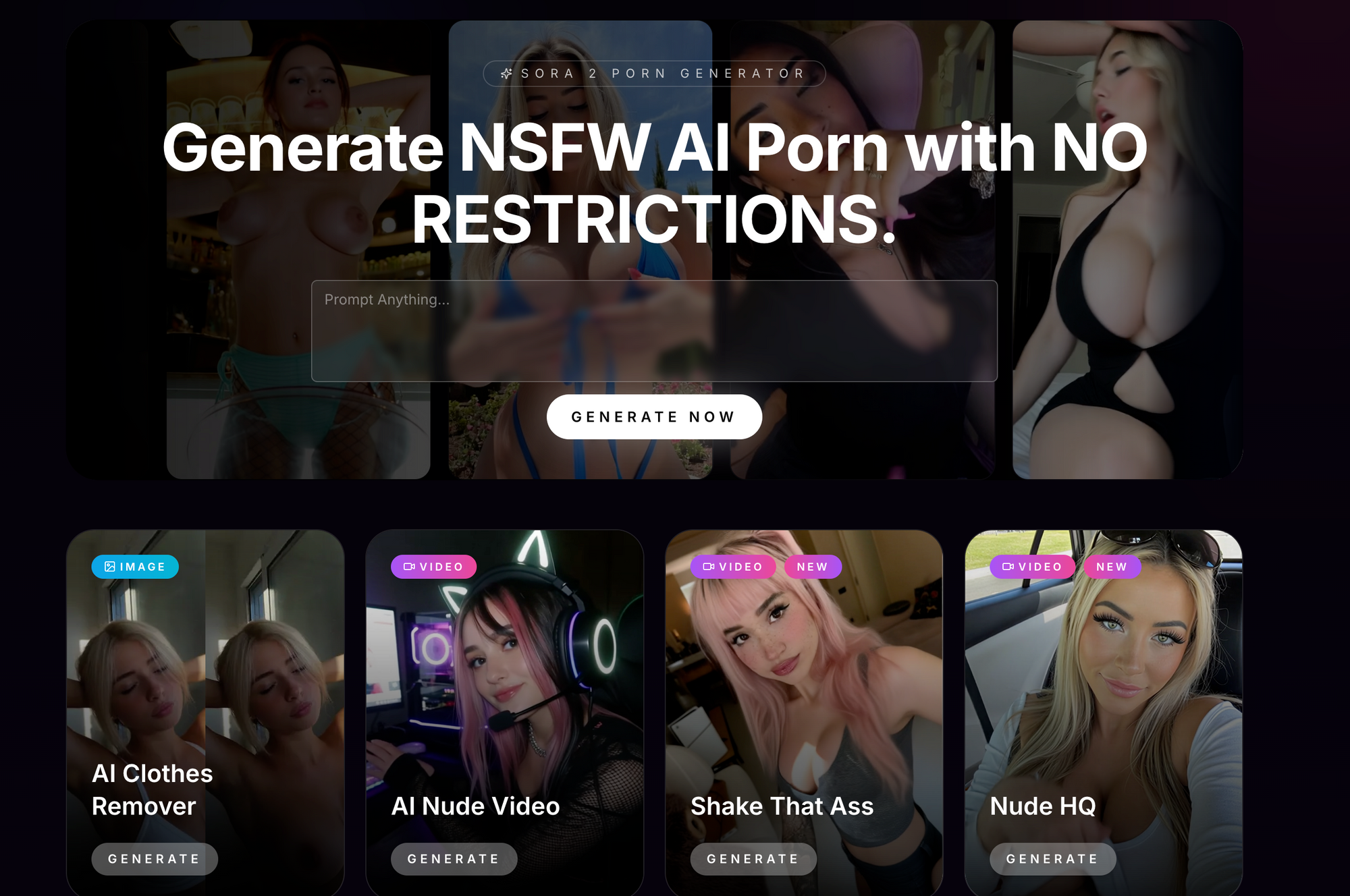
NSFWSora.ai revolutioniert mit Sora-AI-Pornovideos, klont OpenAI-Tech ohne Filter für unzensierte Adult-Clips. Free-Tier: 20 Videos/Tag (5-20s), keine Wasserzeichen, Fokus auf dynamisches NSFW wie Gangbangs oder Solo-Masturbation.
Schlüsseleigenschaften:
- Text-zu-Video-Porno: „Busty MILF Deepthroating, Cumshot-Finish, realistische Motion“.
- AI-Nude & Undress: Statik-zu-Video-Upgrades.
- Sora-Imitation: Flüssige Physik, Lippensync-Stöhnen, Multi-Winkel-Kameras.
- Batch & Edit: Ausgaben remixen.
So funktioniert's: Szene beschreiben > Generieren > Download. Vorteile: Grok fehlt natives Video; das liefert kinematografischen Dreck. Nachteile: Längere Generierung (30s+).
Ideal für Motion-Fetischisten. NSFWSora.ai strahlt bei Realismus mit lebensechten Bewegungen – Haare wehen, Brüste wackeln, Flüssigkeiten tropfen überzeugend. Prompts spezifizieren Kamera: „POV Handkamera, zitternd im Höhepunkt“. Handhabt komplexe Interaktionen wie Multi-Partner-Szenen fehlerfrei.
Free-Videos exportieren in 1080p, upgradbar auf 4K. Edit-Tools erlauben Clip-Verlängerung oder Element-Wechsel post-Generierung. Physik-Engine simuliert Gravitation, Hüpfer und Squirts präzise, überholt Konkurrenz.
#4: Onlyporn.ai – OnlyFans-Stil AI-Porno-Creator

Onlyporn.ai ist Ihre AI-OnlyFans-Fabrik: Custom-Pornobilder/Videos, Undress, Face-Swaps. Free: Unbegrenzte Low-Res-Previews, 50 HD/Tag.
Schlüsseleigenschaften:
- Porn-Gen Pro: Hyperreal Celebrities, BBW, Shemales.
- Instant Adult-Content: Faces in XXX-Szenen swappen.
- NSFW-Video: Kurze Clips aus Prompts.
So funktioniert's: Upload/Face-Swap > Prompt > Generieren. Vorteile: Maßgeschneidert für monetarisierbares Porn. Nachteile: Upscale-Paywall.
Onlyporn.ai spezialisiert sich auf Profi-Ausgaben, imitiert OnlyFans-Ästhetik mit weichem Licht und teasing Posen. Face-Swaps sind nahtlos, verschmelzen Celeb-Ähnlichkeiten mit Custom-Bodies. Videos fangen Signature-Moves wie Twerking oder Stripping ein.
#5: nanobanannsfw.com – Nano Bananas Scharfe Frontier
nanobanannsfw.com nutzt fortschrittliche Modelle für NSFW-Bilder via Prompt-Engineering. Free Online-Galerie/Prompts; umgeht Filter für Nudes (keine vollen Genitalien, aber hautintensiv).
Schlüsseleigenschaften:
- NSFW-Prompt-Hub: 8k+ scharfe Generierungen.
- Bild-zu-Bild: Erotische Edits.
- Unzensierte Hacks: Getestet für explizite Ergebnisse.
So funktioniert's: Prompt einfügen > Generieren. Vorteile: Kostenlos, nuanciert. Nachteile: Weniger explizit.
Toller Grok-Kompagnon für subtile Kinks, mit Prompts für künstlerische Nudes und teasing Enthüllungen.
Einleitung: Warum Alternativen zu Grok für unzensierten NSFW-Inhalt suchen?
Grok AI, entwickelt von xAI, hat die KI-Interaktionen revolutioniert dank seiner witzigen Persönlichkeit, leistungsstarken Bildgenerierungsfunktionen über Flux-Integration und relativ laxen Inhaltsrichtlinien im Vergleich zu Konkurrenten wie ChatGPT oder Gemini. Im Jahr 2026 erlaubt Grok die Erstellung von NSFW-Bildern, einschließlich expliziter Elemente, was es zu einer herausragenden Wahl für Erwachseneninhalt-Enthusiasten macht. Allerdings stoßen Nutzer oft auf subtile Einschränkungen: gelegentliche Zensur bei extremen Prompts, Ratenlimits im Free-Tier, Wasserzeichen oder ethische Barrieren, die hyperspezifische Fetische, Deep-Nudes oder Videogenerierung blockieren. Für diejenigen, die wirklich unzensierte und kostenlose NSFW-KI-Tools verlangen – denken Sie an Instant-Undress-AI, Pornovideogeneratoren, Ahegao-Gesichter und Bildbomben ohne Anmeldung – leuchten dedizierte Alternativen heller.
Schlussfolgerung: Entfesseln Sie Ihre Fantasien Sicher
Diese Top 5 – angeführt von FluxNSFW.ai – bieten überlegenes kostenloses unzensiertes NSFW gegenüber Grok: mehr Modelle, Videos, null Blockaden. Starten Sie mit #1 für Bilder, #3 für Videos. Priorisieren Sie immer Ethik/Privatsphäre; nutzen Sie VPNs. Zukunft? Erwarten Sie wildere Klone. Tauchen Sie verantwortungsvoll ein – Ihre schmutzigsten Träume warten.
from Anakin Blog http://anakin.ai/blog/grok-alternatives-de/
via IFTTT